About Me
Michael Zucchi
B.E. (Comp. Sys. Eng.)
also known as Zed
to his mates & enemies!
< notzed at gmail >
< fosstodon.org/@notzed >

Hacking Life
Ahh it must be the yearly update-the-blog time. I will go check
... early July last year, so a little late but not far off. I
usually think about posting because a) I'm depressed more than
usual, and; b) winter sucks. The two usually conincide anyway.
Been a long year.
I was spending way too much time and money out of the house all
summer. I guess it had it's moments but ultimately it was pretty
empty, and beers at the pub are getting expensive. I have a few
good friends but they seem to be dwindling and I can't seem to
make any new ones. Or somehow end up with whomever's left over
and find out they've been left-over for a reason. Then things
went downhill a bit.
Death in the Family
The old lady died about 3 months ago and while I hadn't seen her
for years watching her dying in the hospital was pretty traumatic,
plus it had me thinking about things like our childhood, my two
dead brothers, and that I never really had a father because he
died so young. Plus I had to identify the body twice which was a
whole barrel of fun. Caught up with some brothers and other
family I hadn't seen in years which was something I suppose.
That sort of indirectly lead to a bit of a burn-out and I stopped
going out for weeks and I've spent a lot of the time since just
around the house. Longest I went was 3 weeks without leaving the
house or yard at all but I'm trying to get out at least once a
week at the moment even if I don't always enjoy it a lot (it's had
it's moments). I hadn't been riding much anyway because of the
weather and I've been doing even less since. Lost a bit of weight
(5%?) — which is mostly ok but I don't really need to lose
any more. Saved quite a bit of money. Bought a 3D printer.
Hacking
Since I've been home a lot I've been doing lots and lots of
programming, in part because I just feel shithouse If I'm not
keeping completely busy. A way to pass the time and keep my mind
occupied. I should probably include some screenshots and so on
down here but I can't be arsed today — I'm just feeling
tired and over it.
When I got the 3D printer I spent a lot of time playing around in
OpenSCAD and OrcaSlicer. They're such a massive pain to get
running on slackware and gentoo I was first using a virtual
machine with ubuntu on it - but that was so fucking slow with
OpenGL it was barely useable. Eventually I worked out how to get
an ubuntu environment running via chroot and that fixed the
performance problems at least. They're still a pain to setup -
appimage is the best of the worst, but even in ubuntu the python
version mess (each minor version breaks comatibility) means i'm
running an older version of OpenSCAD. Anyway I got into making
some interesting designs for a few weeks; parameterised project
boxes, a power button for my pc, and a water-cracker biscuit
cutter, amongst other things. OrcaSlicer is almost right but I
can't get the first later filled enough. I ordered another 8Kg of
different plastics and then built a glass and wood cabinet for the
printer out of scrap (and a 3d printed set of hinges) ... and then
haven't touched any of it since. Half the house looks like an
ali-express delivery truck crashed into it (not that I would get
filament from there, it's one of those odd products that's cheaper
just getting locally).
Because the CAD software was a bit pants I looked into that quite
a bit, played with manifold some, worked a lot on trying to get
signed distance fields to create a high res high quality manifold
in reasonable time and space. I failed so far; it's a hard
problem and marching cubes doesn't cut it. I did generate some
interesting arty pictures though, especially in the 2D versions.
As an aside all the big numerical packages are going heavily into
templated C++. It's a massive pita when you try to compile
anything that uses them - incredibly slow build times, cascading
graphs of obscure dependencies, and then there's cmake. Why, just
why. It barely works outside of the original developers
environment and then the cmake version bumps and breaks even that.
What a disaster for free software and software reusability.
JavaFX
I hit an annoying performance bug in JavaFX along the way and
ended up spending a few late nights on a wet weekend finding out
why. I can't believe it uses gdk_add_timeout to perform frame
timing! Ugh. The man page even says it's completely unsuitable
for this, apart from only having millisecond precision it isn't
free-running so is guaranteed to drift. There seems to be some
logic in JavaFX to handle this sort of timing; but none of it ever
seems to get called.
But that wasn't the performance problem; if
you add an animation it just runs the animation (and all the
update and redraw logic) absolutely flat-chat as described
in JDK-8210547.
It only appears smooth because the monitor is still only updating
at the monitor frame-rate. After a lot of faffing about I worked
out how to vsync in OpenGL and a possible place to hook it into
the rendering pipeline and wrote a patch for it. It's almost
perfectly smooth with the patch on, only runs the animations once
per frame and so uses far less cpu time.
It's not perfect because it overrides all animations to run at the
video frame-rate (not a bad thing tbh), and the pulse timer is
based on some point soon after the vblank wait. Which isn't great
because it means maximum latency between calculation and display,
but it's an interesting start. And when you don't have an
animation active it is still held up by the terribly choice of
gdk_timeout timing so occasionally re-runs animations (the
animation system does this anyway itself, as is always calls an
animation at the start and finish, even if it's a cyclic
animation) or visually drops a frame.
Anyway before I spent the weekend on it I sent a questing post to
the javafx list but never got a reply because you have to
subscribe first (obvious in hindsight but I was being optimistic
given the way the page is presented). Not sure if I'll bother
trying to subscribe or sending them the patch, the project seems
deadish which really sucks as much of the code really is very
nice. There's some other odd decisions - each window gets it's
own rendering context but there is only a single rendering thread.
So once you get high frame-rates and multiple windows the
GLContext switching time grows significant. It's also fairly
complex so it's hard to work out how to improve it.
notzed.nativez
Thinking about using manifold from java led me to working on
on notzed.nativez (aka
NativeZ) again for a bit.
I spent a stupid amount of time on it. I've now completely dropped
the perl generator - I just never used perl enough to really be
proficient in it and all the neat little tricks I managed to work
out in the generator I forgot about when I revisited it often
years later. The Java version is actually smaller, faster, much
easier to follow and even does more; for the most part anyway. I
spent (or wasted?) excessive time on code size reduction and
re-use just because I could - I think I rewrote the template
system about 3 times in a week. I also improved the gcc plugin
output a bit.
As part of that effort I also revisited
the java.make
project. I added support for junit5 and continue to tweak and
improve the makefile. I have another related side-project that
I've been exploring for a while (years?) to improve compile times
and accuracy for Java builds (called 'notzed.buildz'). As part of
that I have a javac compile server which can be started and then
called locally to run the compiler from a script thus avoiding jvm
start-up time. But the old version uses jdk.httpserver and a
messy startup mechanism so was a bit clumsy/hard to secure. I
explored using java.rmi to run a local server - wasted almost a
whole day finding out you need to run the the Registry locally for
it to run at all without a now completely-missing security manager
(internet search is getting so useless). And when I got it
working fine I gave up because it still needs quite a bit of jvm
start-up time to run the tiny java.rmi client so just isn't worth
it. I ended up writing a single-file-java implementation of a
service which listens to a unix domain socket and implements http
using it's own simplified implementation (jdk.httpserver can only
work on Inet sockets), it's small (under 300 lines, under 130 if
you only count ';') and simple and easy to start and stop from a
bash script and invoke using curl.
Another part of that code-base is a dependency calculator. I had
(of course) my own simplified ClassFile scanner but now OpenJDK
comes with one so I converted the code over to use that instead -
although the api is quite different in practice it was almost
trivial to change they both mirror the ClassFile format itself in
macro. Actually I rewrote the dependency calculators a couple of
times too and am still not really happy with them - the code is
straightforward, it's just bulky because there are so many
repeated steps and I can't decided what outputs I ultimately want.
For example I think I can write a fairly small bit of code that
can scan a tree of classes and a tree of sources and determine
which classes are stale and can be deleted. javac
has a module compilation mode but it doesn't perform this step so
it's possible to get inaccurate (stale classes not being deleteD)
and incomplete builds (dependent classes not being rebuilt) that
wont run. I'm still thinking about it, no rush, and nobody else
gives a shit anyway.
I didn't expect it to be nearly as complex as it was to
process a --module-source-path which can include
bash-like brace
expansions. My final solution compiles it into a simple
programme which describes the graph linearly and then executes it
with a simple stack machine. Still so much code for such a
seemingly simple convenience.
The original project was quite old - at the time they were
relatively new or at least I hadn't used them much so I was adding
lambdas and streams to everything and it turns out that's messy as
fuck when you're dealing with i/o interfaces; so a lot of that
went away and greatly greatly simplified everything. As I never
really saw the need before and just haven't been hacking a lot for
a few years; this also exposed me to some of the newer Java
constructs like pattern matching. Which has been more useful than
I thought for tightening up code (in normal expressions) and
avoiding mis-handled cases (in switch expressions or statements).
mal
The last few days I came
across make a lisp
(mal) and thought it might be a fun diversion for the weekend.
Unfortunately it wasn't nearly as fun nor as informative as I had
expected. Like most things lisp-related the guide was written
from the perspective of someone who thinks lisp is every computer
language, some of it was just not well defined and a lot of the
structure suggested didn't make sense when I ran out of steps to
perform. Also if you're going to the point of creating a new
clean lisp why so many weird hold-overs from decades ago? I've
gotten to the point of it self-hosting and even cleaned up and
tuned the code a little bit but it hasn't given my any greater
insights into lisp than the little I already had. Plus the mal
project is basically dead anyway; seems clojure was the last great
gasp of the lisps and the language is finally dying. Not sure if
i'll bin it, archive it on code.zedzone.au, or archive it as a
fork on github, as a potential scripting language for my projects
I'm just not sure I GAF.
stuff
There's been other diversions along the way (I do have a LOT of
free time); from code tinkering, exploring new software (Netbeans
is really giving me the shits lately), to building physical
things, exercise because my leg (post hip replacement and lack of
riding) seems to have lost a lot of strength and mass, plus my
arms are starting to hurt from all the M-x-ing. Walking,
drinking. Trying to keep warm; the Reynaud's has been
particularly bad this year and i'm generally just feeling
miserably cold if it's not warm and sunny. And miserably
miserable. Totally isolated and utterly alone. Watching some TV
shows (sci-fi), reading books (also sci-fi), a little gardning.
Finally cancelled my PS+ subscription - barely touched it for ages
and I don't play online. Somehow losing weight seems to have
increased my sleep apnoea so that's been bothering me more lately
- feeling so tired every time you wake up makes it hard not to
just end up having a shit waste-of-a-day. I feel tired. Maybe
i'm not eating right.
More Maths
It wasn't a problem with the fixed divisor of 10 but I missed that
the additions in the mulh() routine used in the
previous post can overflow which I discovered while trying to
implement a 32 bit version
of division
using Newton's Method to find the reciprocal.
Here's 3 different versions which address it.
Using a 64-bit addition, which isn't very fast:
uint32_t mulh(uint32_t a, uint32_t b) {
uint32_t ah = a >> 16;
uint32_t al = a & 0xffff;
uint32_t bh = b >> 16;
uint32_t bl = b & 0xffff;
uint32_t c = ah * bh;
uint32_t d = ah * bl;
uint32_t e = al * bh;
uint32_t f = al * bl;
uint32_t g = f >> 16;
// calculate ((d + e + g) >> 16) without overflow
uint32_t h = ((uint64_t)d + e + g) >> 16;
return c + h;
}
Breaking the addition into 16 bits and using 32-bit addition seems to be the best idea:
uint32_t mulh(uint32_t a, uint32_t b) {
uint32_t ah = a >> 16;
uint32_t al = a & 0xffff;
uint32_t bh = b >> 16;
uint32_t bl = b & 0xffff;
uint32_t c = ah * bh;
uint32_t d = ah * bl;
uint32_t e = al * bh;
uint32_t f = al * bl;
uint16_t g = f >> 16;
// calculate ((d + e + g) >> 16) without overflow
uint32_t h = (d >> 16) + (e >> 16);
uint32_t l = (d & 0xffff) + (e & 0xffff) + g;
return c + h + (l >> 16);
}
Detecting overflow and manually calculating the carry bits afterwards:
uint32_t mulh(uint32_t a, uint32_t b) {
uint32_t ah = a >> 16;
uint32_t al = a & 0xffff;
uint32_t bh = b >> 16;
uint32_t bl = b & 0xffff;
uint32_t c = ah * bh;
uint32_t d = ah * bl;
uint32_t e = al * bh;
uint32_t f = al * bl;
uint16_t g = f >> 16;
// calculate d + e + g (may overflow)
uint32_t x = d + e;
uint32_t y = x + g;
// calculate carrys
uint32_t p = ((d | e) & ~x) | (d & e);
// g can be ignored because the high bits are 0
uint32_t q = x ^ y;
uint32_t o = ((p >> 31) + (q >> 31));
return c + (y >> 16) + (o << 16);
}
I think it should work anyway. It requires more bit manipulation
than I'd expected.
C sucks
The previous version also included a subtle bug - one which only
shows up in specific circumstances. It has to do with c promotion
rules and what I think is pretty inconsistent results but it
probably falls into the 'undefined behviour' of c.
uint16_t ah = ...;
uint16_t al = ...;
uint16_t bh = ...;
uint16_t bl = ...;
uint32_t c = ah * bh;
To calculate c, ah and bh are
promoted to int per the c specification,
not unsigned int as you'd expect. Thus if the msb of c is
set it's actually an overflow because the multiply is considered
signed. This can lead to some pretty weird results if the code is
optimised by the compiler:
uint16_t ah = 0xffff;
uint16_t bh = 0xffff;
uint32_t c = ah * bh;
printf(" c = %08x\n", c);
printf(" c >> 30 = %08x\n", c >> 30);
printf(" c >> 31 = %08x\n", c >> 31);
printf(" c < 0 = %d\n", (int32_t)c < 0);
-->
c = fffe0001
c >> 30 = 00000003
c >> 31 = 00000000
c < 0 = 0
I think that result is a bit inconsistent - if it's it's going to
enforce an unsigned overflow limit (i.e. 2 unsigned multiply's can't
be negative) it should do it everywhere (i.e. the result should be
truncated). But that's c I suppose. I actually filed a bug with
gcc because it's a pretty naff result but it was pointed out that
it's just a part of the promotion rules and so now I feel a bit
embarassed about doing so; particularly since only came about
because I was using uint16_t to save some typing.
I also have to remember it's never a bug in the compiler. The last
time I filed a bug for a compiler was using the Solaris cc
around 26 years ago and I still feel shame when I think about it.
Also just don't bother with small integers aside from storage, you
never know what you're gonna get.
Division by Multiplication
Anyway this is the result of the conversion of the routine from the
other blog mentioned above to 32 bits.
// Derived from 16-bit version explained properly here:
// <https://blog.segger.com/algorithms-for-division-part-4-using-newtons-method/>
// re16[0] should be 0xffffffff but it can lead to overflow
static const uint32_t re16[16] = {
0xfffffffe, 0xf0f0f0f0, 0xe38e38e3, 0xd79435e5,
0xcccccccc, 0xc30c30c3, 0xba2e8ba2, 0xb21642c8,
0xaaaaaaaa, 0xa3d70a3d, 0x9d89d89d, 0x97b425ed,
0x92492492, 0x8d3dcb08, 0x88888888, 0x84210842,
};
// esp32c3 96 cycles using mulh instruction
// esp8266 216 cycles using second mulh routine above
udiv_t udiv(uint32_t u, uint32_t v) {
int n = __builtin_clz(v);
// normalised inverse estimate
uint32_t i = v << n >> 27;
uint32_t r = re16[i - 16];
v <<= n;
// refine via Newton's Method
r = mulh(r, -mulh(r, v)) << 1;
r = mulh(r, -mulh(r, v)) << 1;
// quotient, denormalise, remainder
uint32_t q = mulh(u, r);
q >>= 31 - n;
v >>= n;
r = u - q * v;
// check remainder overflow, 2 steps might be needed when v=1
if (r >= v) {
q += 1;
r -= v;
if (r >= v) {
q += 1;
r -= v;
}
}
return (udiv_t){ q, r };
}
Depending on the mulh() routine used this is nearly the
same speed as div() on an esp32c3 (which is interesting
given it has a divu instruction), and 2.25x fater
than the div() library call on esp8266.
Quicker divmod on esp32/esp8266
The reason I looked into this is a bit silly but in short I've come
up with some code that does a divide/modulo by 10 somewhat faster
than the C compiler comes up with. A fairly straightforward
bit-shifting implementation improves over the compiler supplied one
on esp8266 but that's only the start. I eventually came across some
xtensa assembly language code in Linux for div/mod but I haven't
investigated, this is just looking at c.
Slow Divide
The esp8266 doesn't have a divide function so it is implemented
using a standard bit-based long division algorithm. The RISCV cpu
in the esp32c3 does have one but it's pretty slow. Below is an
example of a straightforward divmod implementation with
a few basic improvements.
// udiv32 libc.div() c / and %
// esp32c3 290 87 80 cycles
// esp8266 320 490 470
udiv32_t udiv32(uint32_t num, uint32_t den) {
uint32_t r = 0, q = 0;
uint32_t bit = 1 << 31;
// shortcut low numbers (and avoid 0)
if (num < den)
return (udiv32_t){ 0, num };
// shortcut high numbers
int f = __builtin_clz(num);
// we know this bit is set so take it
bit = bit >> (f + 1);
num = num << (f + 1);
r = 1;
while (bit) {
r = (r << 1) | (num >> 31);
num <<= 1;
if (r >= den) {
r -= den;
q |= bit;
}
bit >>= 1;
}
return (udiv32_t){ q, r };
}
It's running time depends on the inputs but on an esp8266 it's
around 50% faster than div or simply using { num
/ div, num % div }. On the other hand it's 1/4 of the speed
on an esp32c3 which has divu and remu
instructions (of unknown implementation and timings).
There are a few (micro) optimisations which help on most cpus:
- Using
clz() to skip to the first set bit in the
numerator, even if there's no clz instruction it's
usually something better than testing each bit one by one;
- Moving the first iteration outside of the loop since we're already at a set bit;
- Avoiding a separate loop counter by using the bit itself;
- Avoiding masks in the bit copy by taking the top bit from the numerator.
One odd thing I noticed when verifying it is that intel cpu's can't
shift a 32-bit value by 32 bits, so without the shortcut exit the
result will be incorrect if num is 1. But only on
intel.
Fast Multiply
I suppose that was a bit of a win for fairly simple C but given
multiply isn't slow on the cpu's it's possible to improve the
results for specific values by pre-calculating a multiplication
constant.
A fixed point division can be implemented by a multiply of the
inverse and a shift. Having a 32-bit implied shift from
a mulh instruction gives the obvious choice for the
shift and provides the maximum precison possible. The inverse
constant is easy to calculate (using 33 bit arithmetic):
SCALE = (1 << SHIFT) / den
= (1 << 32) / 10
= 429496729
= 0x19999999
Then to calculate the division requires the high result of a 32x32
multiply.
uint32_t div10(uint32_t num) {
return (uint64_t)num * 0x19999999 >> 32;
}
Unfortunately if you try using this directly you find it is
incorrect quite often - all(?) multiples of 10 are out by 1 for
instance and it gets worse after num gets very large -
larger than 0x40000000. This might not be a problem
for some applications but I needed a correct result. I tried adding
some magic bits to the multiplicand - which helped - but it can't
cover every possible input and and requires feedback to correct.
Fortunately over the full range of input the error is no more than
1/2 (or a remainder overflow of +5), and since this code is also
interested in the remainder it can then be used to correct the
error. Thus:
// esp32c3 33 cycles
// esp8266 124 cycles
udiv32_t udiv10(uint32_t num) {
uint32_t q = (uint64_t)num * 0x19999999 >> 32;
uint32_t r = num - q * 10;
if (r >= 10) {
r -= 10;
q += 1;
}
return (udiv32_t){ q, r };
}
On an esp32c3 this is nearly 3x faster than the compiler generates
using div/rem instructions, but obviously
it is hardcoded to the single denominator of 10.
An esp8266 doesn't have a mulh instruction and the
compiler generates a full 64 bit intermediate result from a library
call - however this is still 5x faster than div(). So
the next obvious step is to try to just calculate the high bits of
the multiply without retaining the rest. It turns out you can't
save many operations but the operations you can save are fairly
expensive on these cpus - 64 bit addition is a bit messy without a
carry flag.
Using long multiplication provides the solution:
/*
* ah al
* bh bl
* -------------------
* ah.bl al.bl
* + ah.bh al.bh
* ===================
* <<32 <<16
*/
// esp32c3 40 cycles
// esp8266 58 cycles
udiv32_t udiv10(uint32_t num) {
uint16_t ah = num >> 16;
uint16_t al = num;
uint16_t bh = 0x1999;
uint16_t bl = 0x9999;
uint32_t c = ah * bh;
uint32_t d = ah * bl;
uint32_t e = al * bh;
uint32_t f = al * bl;
uint32_t t = d + e + (f >> 16);
uint32_t q = c + (t >> 16);
uint32_t r = num - q * 10;
if (r >= 10) {
r -= 10;
q += 1;
}
return (udiv32_t){ q, r };
}
Each multiplication result 'column' is 16 bits wide with some
overlap so a few shifts are required to line everything up and not
lose any bits.
On an esp8266 this uses the mul16u instruction directly
and ends up about 2x as faster again, or around 10x faster in total
than using div.
This isn't much slower on an esp32c3 either, possibly
the mulhu instruction is slower than mulu;
it's cycle timing doesn't appear to be publically documented and I
haven't tried timing it as yet. I'm also timing call overheads
which are significant at this range of cycle times (17-22 cycles).
A bit more juice
This can be improved a tiny bit more. It turns out for this case
that a slight adjustment to the multiplier improves the accuracy of
the initial result significantly. By adding 1 to the multiplcand
will provide an exact result for every num from 0 to a
bit over 0x40000000. This is quite a bit better but it
still needs correction and the error will be in the other direction
- the remainder can go negative.
The mulhu friendly version:
// esp32c3 30 cycles
// esp8266 123 cycles
udiv32_t udiv10(uint32_t num) {
uint32_t q = (uint64_t)num * 0x1999999a >> 32;
uint32_t r = num - q * 10;
if ((int32_t)r < 0) {
r += 10;
q -= 1;
}
return (udiv32_t){ q, r };
}
Apart from being correct more often the negative test is cheaper on
many cpu's since it doesn't require a comparison first. Two's
compliment arithmetic means the sign still works as a test on an
``unsigned'' number.
The mul16u friendly version:
// esp32c3 37 cycles
// esp8266 56 cycles
udiv32_t udiv10(uint32_t num) {
uint16_t ah = num >> 16;
uint16_t al = num;
uint16_t bh = 0x1999;
uint16_t bl = 0x999a;
uint32_t c = ah * bh;
uint32_t d = ah * bl;
uint32_t e = al * bh;
uint32_t f = al * bl;
uint32_t t = d + e + (f >> 16);
uint32_t q = c + (t >> 16);
uint32_t r = num - q * 10;
if ((int32_t)r < 0) {
r += 10;
q -= 1;
}
return (udiv32_t){ q, r };
}
The timings were taken from the cpu cycle counters but are
approximate as they depend either a lot (for the shift
implementation) or a tiny bit on the inputs. They also include the
overheads of function calls, for these systems size is important so
it's probably necessary anyway but for comparison this is the timing
of non-functional calls tested the same way.
// esp32c3 17 cycles
// esp8266 22 cycles
udiv32_t udiv_null(uint32_t num) {
return (udiv32_t){ num, num };
}
Not sure it was the best use of a whole day but there you have it.
Well I did mow the lawn.
Driver for HLK LD2410C
I've been playing with the
tiny HiLink
HLK-LD2410C human presence sensor and an ESP32C3 and decided to
write a fairly complete driver for it as I couldn't find one apart
from a partial implementation in c++ for the Arduino platform.
Below is snippet of an example of how to use it.
#include "esp-ld2410.h"
...
// Initialise device on UART 1 using
// Default factory baudrate (256000)
// GPIO_NUM_1 for txd (connected to module rxd),
// GPIO_NUM_0 for rxd (connected to module txd),
// No digital signal
ld2410_driver_install(UART_NUM_1, LD2410_BAUDRATE_DEFAULT, GPIO_NUM_1, GPIO_NUM_0, GPIO_NUM_NC);
// enable full-data (engineering) mode
ld2410_set_full_mode(UART_NUM_1);
// Retrieve and print data.
// It may take a little while for data to be valid.
while (1) {
const struct ld2410_full_t *data = ld2410_get_full_data(UART_NUM_1);
printf(" detected: %s %s\n",
data->status & LD2410_STATUS_MOVE ? "moving" : "",
data->status & LD2410_STATUS_REST ? "resting" : "");
vTaskDelay(pdMS_TO_TICKS(1000));
}
Pretty much every feature is supported apart from anything bluetooth
related but that isn't difficult to add.
Internally it uses a daemon task to monitor the serial port and
manage communications with the device. For example most settings
and queries must be performed after switching to 'command mode' -
this is handled automatically and efficiently by the daemon task.
This is my first attempt at anything sophisticated with FreeRTOS so
my choices of IPC primitives and so on may not be those I'd choose
with experience.
I'm not really sure what I'm going to do with the sensor but at
least I have a platform for experimentation with it.
There is some more information and links on
the esp-ld2410 project page.
Electrified Kilt!
I caught up with some old mates recently and one of them gave me a
couple of ESP-01 board to play with. I wasn't really sure what I
was going to do with them, one plan was a wifi-connected irrigation
controller just for something to poke at and to learn about the
devices and the i/o. But this act of generosity cascaded into a bit
of a spending spree on aliexpress where i've added some esp32-c3's,
a bunch of sensors, relay boards, power modules, solderless
breadboards, LED strips ...
Once I got them working I wasn't really sure what to do with them, I
have some ideas for the light strips for xmas but since I had them
and winter solstice was coming up I decided to do something a bit
silly and see if I could successfully 'electrify' one of my kilts!
The pictures don't really do it justice - the leds are very bright
at night and very colourful and animate very smoothly. I'm using a
Makita battery which is a bit hefty to hang off my belt but it's
what I had available and has enough juice to run it for about 20
hours or something stupid.
We're having a mid-winter 'light show' thing at the moment and I
wore it out again last night (the opening night), I should've done
a mainy on foot but I didn't really have the gumption for it and
just stayed in the one pub all night. One does feel a bit self
concious wearing it although on the solstice I walked home lit up
like an xmas tree some time late at night (about an hour's walk).
Hacker Hacking
It turned out to be more work than I expected, from working out how
to lay out and attach the leds (sewing them on, so I need to unsew
to wash it), soldering up an adapter board, plus of course all the
coding.
I started with some of the code
in FastLED but all I really have
left is some of the colour palettes.
I used Arduino initally to get the devices 'live' but quickly moved
onto the FreeRTOS sdk - Arduino is interesting enough but its' a bit
clunky to work with compared to proper tools. And I gotta say some
of the quality of code is pretty low. I also started the LEDs
showing with an ESP-01 board (esp8266) but then moved to an ESP32-C3
which is a much more interesting board. It's the first time I've
played with a RiscV processor - TBH I find some of the ISA decisions
a bit weird but due to the simplicty of the instruction set and
enough registers the compiler mostly does a pretty good job of
compiling it. Mostly. It does some weird shit when you return a
structure in registers (a 2-vector) like move the stack pointer down
and up and doesn't store anythin gon the stack.
The first time I wore it for the solstice I noticed the colours were
a bit flat - the Perlin noise from FastLED wasn't being scaled qutie
correctly so it was missing a big part of the range. I experimented
a lot with it but ended up scapping it and converting the Java
implementation of Simplex Noise from Stefan Gustavson into C and
then into fixed-point. I also experimented with a lot with the
code, various micro-optimisations and using a hash function rather
than a permute table, gradients generated from bits or from lookup
tables, and so on.
I was going to write a text scroller and even found (and created)
some tiny fonts. But in the end I couldn't think of anything
worthwhile to write so I decided not to bother coding it up. I
created some tiny animations but they looked a bit shit with such
a small number of pixels to work with so decided to drop them as
well. Instead I render some simple geometric shapes on the fly
using signed
distance fields which also let more easily play with the
colours. This was another journey into writing some fixed-point
affine transforms, sincos functions and inverse square root which
the internet provided starting points for which I cleaned up or
simplified for better RISCV optimisation. And I implemented a
version of the R250 random number generator but with a smaller
number of coefficients and parameter choices which sped it up a
bit more and use that to drive everything. I even hooked up a web
server I wrote (not using the ESP SDK one) that you can connect to
via wifi but I couldn't really think of anything useful to do with
it.
I was worried about the cost of calculation and spent a good few
days trying various optimisations but the simplex algorithm was
already significantly faster than the noise routines from FastLED
and in the end it wasn't a problem. I think the fastest 3D
simplex calculation was about 280 cycles, the FastLED 3D noise was
about 520 iirc. There are only 50 leds and the colours are easily
updated 125 times/second - that's with up to two planes of 3D
Simplex Noise or a basic SDF graphic. One somewhat small but still
effective optimisation technique to remove the 8 and 16 bit
integral types used heavily in ARM or AVR code - these usually
require extra operations since the RISCV CPU has only 32 bit types.
The gamma curve of the leds I have is pretty rough - at the low
end the steps are very noticeable so I implemented 2 bits of
temporal dither (aka 'frame rate control') to try to help. So the
LEDS themselves are actually updated 500 times/second and every
fourth timeout I re-render the graphics. There is more that could
be done to adjust the colour curves and so on but really I
couldn't be bothered. I also didn't investigate the ESP32 timers
and interrupts and just run it off an RTOS timeout handler.
So anyway I came up with 2 different noise types - one a higher
contrast scaled simplex noise with mostly monochromatic palettes,
and a smoother one with more colourful palettes. Apart from the z
dimension the smoother one can also move up or down, left or right.
And 5 different SDF patterns - a line, a cross, a rectangle, half
plane, quarter plane and two quarter planes. These rotate or move
and the line/cross/rectangle are repeated on an 8x8 grid. There's
about a dozen different palettes plus 8 monochromatic ones created
on the fly which can also be complemented (i.e. purple+green or just
purple+black). These run for a randomised time and then slowly fade
into the next routine. One last thing I added was it flashes for 5
seconds every now and then (at different rates) and on a separate
cycle to everything else just to add a bit more bling.
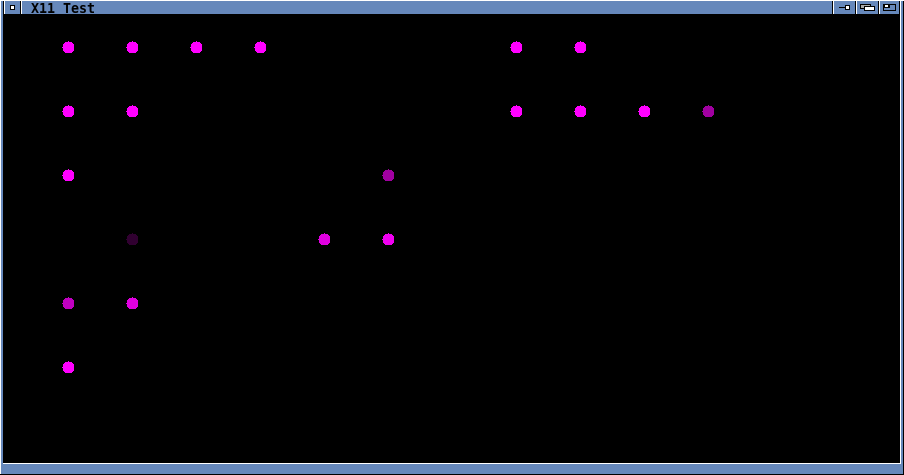
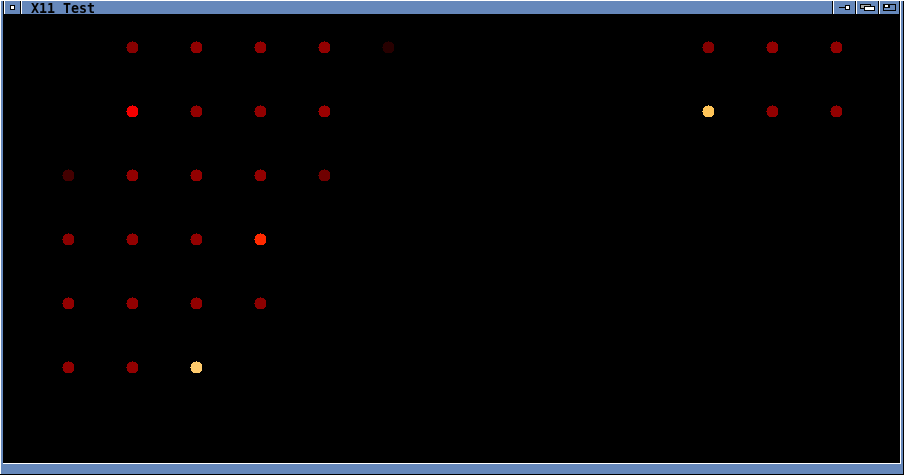
I even wrote an Xlib 'kilt simulator' I could use to rapidly test the
routines!
Ahh well that kept me off the streets for a couple of weeks and
got a few laughs and a lot of weird looks. I'll (probably?)
eventually get around to uploading the code, I have to work out
where I got all the bits from first. I'm not involved with any
forums any more and mastadon isn't really my thing so nobody will
end up seeing it anyway. I filed a bug report with FastLED about
their 8 bit blend function which isn't quite correct.
It was also fun doing a bit of coding again - although CMake could
certainly fuck off. Shit like that puts me off wanting to code
again for a job, although maybe I should start thinking about it
again.
Summer
Well summer finally arrived — only about 2 months late. The
garden's been pretty confused this year but the growing season is
all but done now, but i'm hoping for a few more chillies yet.
My leg is slowly healing, unfortunately I developed bursits due to
dealing with the degrading joint and that has lingered beyond the
hip replacement. The implant is particularly perpendicular which
seems to be adding additional stress on the bursa but I was
probably too active pre and post-operation and aggravated it
further.
I've got some daily physio exercises to move through and that
seems to be helping but it's frustrating I can't ride as much as
I'd like to. Cycling seems to be the main aggravator for the
bursitis which is a bit of a problem when I don't drive. I can
get a cortisol injection if I want but I'm trying to avoid is as
frankly I'm sick of hanging around hospitals and doctor surgeries.
While it's mostly just annoying it can be quite painful and the
main problem is it interfering with sleep which I don't get enough
of anyway. Anyway it seems to be getting better, albeit very
slowly.
I've been spending way too much time and money at the pub drinking
way too much; at least it's mostly been for fun and my mood has
generally been a bit better this year. I've had a couple of low
episodes but I just push through it and try to get out of my head
and my house and they haven't persisted, very much not looking
forward to winter though, It's quite a bleak time even with the
relatively mild winters we experience.
Retirement?
I've just got so much spare time it's hard to fill so I've been
looking at things to do such as reading, cooking, exercising. My
key-lime tree has been shedding excessive fruit so I've had lots
of limes to use up — so I've been making pickles and
chutneys and marmalade's and cordial, and hot sauces. I fermented
1.5kg of chillies that I turned into tobasco-style sauces. I
found a local place to get sauce bottles and small jars although
it's not particularly cheap. I tend to give away a lot of what I
made and the jars and bottles rarely return.
In part due to the hip replacement and in part because I have the
time I've been keeping pretty fit and healthy, right bang on
'ideal weight' for my height. Apart from the obscenely excessive
beer and a bit of a gout flare-up I'm eating very well, it
basically turned into a Mediterranean Diet without intending to.
Greens from the garden, lots of citrus, chillies, nuts, legumes,
soups, a bit of liver once in a while. Not a whole lot of meat
— not because I don't like it I just can't be bothered
cooking it.
Yesterday I did a bit of a budget review and I'm going to have to
either cut back on spending quite a bit or consider working again
at some point. Still I'm going ok considering I haven't worked
for over 3 years and have zero income so there's still no real
rush. I'm getting a bit too comfortable with not having to deal
with all that bullshit and I simply blanch at the thought of
having to work again. Lucky me I guess.
Domain Changed!
I've changed the site domain to zedzone.au. I'm pretty sure I got
everything but if something breaks it breaks and I can fix it as
required. It was a pain in the arse to have to do it but it
didn't take much work.
| Old Site | | New Site |
|---|
| www.zedzone.space | → | www.zedzone.au |
| code.zedzone.space | → | code.zedzone.au |
| zedzone.space | → | zedzone.au |
I've added a permanent redirect from the old .space domain to the
.au domain — but this will only work as long as the domain is
active, and it expires in 7 days.
Domain Change
I got the .space domain because it was cheap but now it's jumped
significantly in price ... so i'm going to attempt to move to zedzone.au.
This might upset things for a little while but so be it, it's not
like this is a heavily trafficked site.
Copyright (C) 2019 Michael Zucchi, All Rights Reserved.
Powered by gcc & me!