
Beyond the ROC
I mentioned a couple of posts ago that i was hitting a wall trying to improve the classifier using a genetic algorithm because the fitness measure i'm using reached 'perfect' ... well I just worked out how to go further.
Here is a plot of the integral of the population density curve (it's just the way it comes out of the code, the reader will have to differentiate this in their head) after 400 and 50K generations of a 16x16 classifier. I now have the full-window classifier working mostly in OpenCL so this only took about 20 minutes.
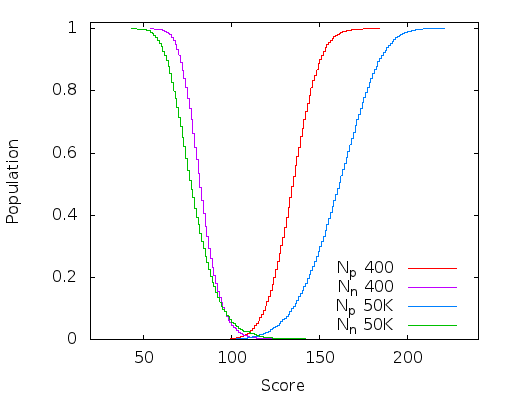
Although a perfect classifier just has a dividing line separating the two populations, it is clear that these two (near) perfect classifiers are not equal (the above plot was generated from a super-set of the training data, so are not perfect - there should be no overlap at the base of the curves). The wider and deeper the chasm between the positive and negative population, the more robust the classifier is to noise and harder to classify images.
400 generations is the first time it reached a perfect ROC curve on the training data. I just let it run to 50K generations to see how far it would get and although most of the improvement had been reached by about 10K generations it didn't appear to encounter an upper bound by the time I stopped it. Progress is quite slow though and there is probably cause to revisit the genetic algorithm i'm using (might be time to read some books).
This is a very significant improvement and creates much more robust detectors.
Because the genetic algorithm is doing the heavy lifting all I had to do was change the sorting criteria for ranking the population. If the area under the ROC curve is the same for each individual then the distance between the mean positive and mean negative score is used as the sort key instead.
The Work
So i'm kind of not sure where to go with this work. A short search didn't turn up anything on the internets and recent papers are still mucking about with MP-LBP and integral images on GPUs which I found 2 years ago are definitely not a marriage made in heaven. The eye detector result seems remarkable but quite a bit of work is required to create another detector to cross-check the results.
The code is so simple that it's effectiveness defies explanation - until the hidden maths is exposed.
I started writing it up and I've worked out where most of the mathematics behind it come from and it does have a sound basis. Actually I realised the algorithm is just an exisiting common algorithm but with a single specific decision causing almost all of the mathematics to vanish through simplification. I first looked at this about 18 months ago but despite showing some promise it's just been pretty much sitting idle since.