
OpenCL Kanade Lucas Tomasi feature tracking
I've added a couple of things to socles, the main being an implementation of Kanade Lucas Tomasi feature tracking. It's just a fairly simple translation of the public domain version here (site seems down at time of writing), with a few tweaks for good GPU performance. Ok it looks nothing like it, but all i did was remove the need for 3 temporary images and the loops to create and use them by noting that each element was independent of the other and so they could all be moved inside of a single loop.
I've only implemented the translation-only version of the tracker, with the lighting-sensitive matching algorithm. The affine version shouldn't be terribly difficult - it's mostly just re-arranging the code in a similar fashion (although the 6x6 matrix solver might benefit from more thorough work).
Really awful screenshot of it in action ... (it's very late again)
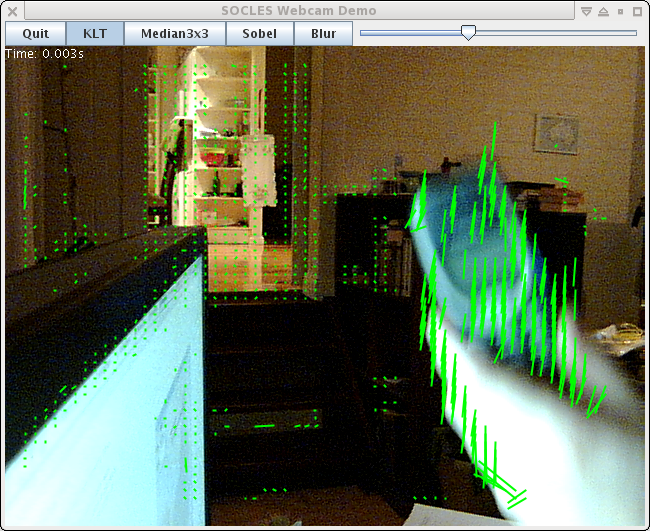
The 3300 regularly spaced feature points above take about 1.5ms to track in GPU time (480 GTX), including all of the image pyramid and gradient image set-up for the incoming frame. It uses 3 levels of pyramid with each 1/4 the size in each dimension of the one below. Most of the points lose track because there isn't enough detail to meet the quality settings, hence the areas with no green dots.
With a CPU implementation the majority of the time is taken in the convolutions necessary to setup the image pyramid - although eventually with enough features one reaches a break-even point. In this case it's about 500uS for the image setup for 640x480 image (3 convolutions at full res, 2 at each subsampling and one resample), and 1ms for the 3300 tracks (i.e. 0.3 microsecond per additional 16x16 feature tracked). Well that's quick enough to keep me happy anyway. At least for now!
I implemented this using a pattern which I've found after much (much) trial and error to be reliably efficient for mapping many types of rectilinear problems to GPU processes, which i'll just call an NxM execution pattern. For a feature-size of 'NxM', the code assigns 'N' threads to each feature, each which works on a column of 'M' rows of data, with the first thread in the sub-group used to tally results and make decisions. A small amount of local memory is used for the partial sums and to share the decisions amongst the threads. These are mapped to a flat work size which is independent of the local workgroup size, which allows for easy tuning adjustments. So a feature size of 9 would be mapped using 7 features if the local work-size is 64, with 15 threads idle (i.e. choose factors of the worksize for best efficiency, but it can still work well with any size). 100 such features would need 15 work groups (ceil(100/7)). The address arithmetic is a bit messy but it only needs to be calculated once on entry, after that it is simple fixed indexing. And since you can reference any memory/local memory by local id 0 you don't have to worry about memory bank conflicts.
I tried many other variations of mapping the work to the GPU and this was by far the best (and not far off the simplest once the fiddly address calculations are out of the way). For example, using a parallel prefix some across all elements with a 3d work size (i.e. 16x16xnfeatures) was about 1/2 the speed IIRC - the increased parallelism was a hindrance because of both the IPC required and the over-utilisation of resources (more local memory and threads).
Update Ok I found a pretty major problem with this mapping of the jobs - early exit of some sub-workgroups messes up the barrier usage which upsets at least the AMD cpu driver. So all threads need to keep executing until they are all finished and then mask the result appropriately, which will complicate matters but hopefully not by much.Update 2 I think I managed to solve it, although I had some trouble with the code behaving as I expected, and got misled by bugs in other kernels.