
Parallel Prefix Sum
14/9/11: added a further paragraph on additional thoughts
Since coming across the parallel prefix sum a couple of weeks ago, a lot of things I need to solve seem to fall into the class of problems it is suited for within OpenCL on GPU platforms. However after a lot of trial and error and experimentation i've found it is usually just slower - sometimes by quite a margin.
In short, it takes advantage of the very high speed local memory ('LS') and parallelism to compute a commutative result from every element to every previous element in log2(n/2) steps.
But with GPU's there are a couple of problems with it:
- Even in the ideal case many of the threads are computing redundant data or not operating (depending how one chooses to implement it).
- A synchronisation step is required after every single operation - which is usually something trivially simple.
The first leads to an over-commitment of threading resources which impacts the scalability as the overall job size increases. And the second leads to very inefficient scheduling even on simple tasks, and a much heavier 'inner loop'.
For example, I implemented a 5x5 maximum operation (for non-maximum suppression peak detection) using a separate X and Y operation (I realise a 5-tap test doesn't really exercise the log2(N) nature of the algorithm much, but more on that later).
My first implementation uses a 16x16 workgroup size (after much experimentation this seems to be the generally best workgroup size for operating on images on my hardware - it leads to an occupancy of 1 and seems to be a good fit for the texture cache configuration). Each local workgroup reads a 16x16 area into LS and then 16 threads work together on each row of result. It only does a couple of 'prefix sum' steps because I only need the result from 4 samples, and I do the last one manually. I use the trick of offsetting the starting point so no thread requires any conditional execution. Finally, it only produces 12 valid results for the 16 inputs since you need overlap.
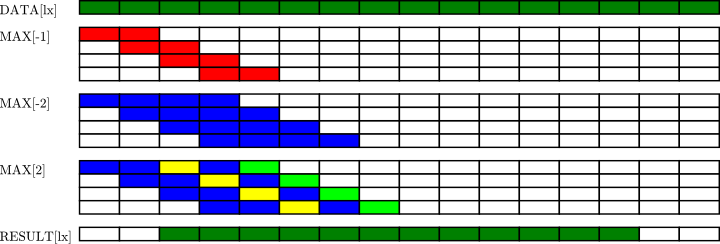
Figure 1: Steps taken for parallel maximum calculation. Only the workings of 4 of the 16 threads are shown.
Because it only generates 12 results it needs to be run 16/12 times the width of the image. This runs in about 65uS on the test data set.
Then I tried a version which reads 2x 16x16 blocks into memory so it can produce all 16 results in one go - unfortunately i've lost the timings and I can't be bothered to re-run it, but i'm fairly confident it wasn't terribly impressive.
Finally I implemented a very simple version which just reads in 2 16x16 blocks into local memory, and then does the operation on the 2 pixels before and 2 pixels after the current location (i.e. an unrolled loop). This was somewhat quicker - 48uS, or about 25% faster.
I didn't bother trying it for the parallel sum case, but I also tried larger window sizes for the simple version - and even at 9 it is still 20% faster than the 5X case for the parallel sum version. And this is for the single channel case - for a 4 channel image you have a 4x LS load, which is not required when it is calculated in registers.
Intuition would tell you that increasing the data-size will eventually lead to a case where it out-performs the simple cases. But the wider the data being calculated the more threads you require and this reduces the opportunity for hiding latencies by letting the GPU schedule independent workgroups. The local store can also be a factor since it too can limit how wide you can go.
I also applied it to (larger) problems where you're only interested in the final result. Because branching is expensive it seems on paper that it doesn't matter if you generate many redundant results since the overall number of steps is much lower - e.g. a 16x16 summation only takes 7 steps rather than 256. Although in reality you break it up into 16 strips 1xwide so it's only 32 steps (16 lots of 16 plus 1 of 16). And it only takes 16 threads rather than 256, so you can execute 16x as many at once for a given number of threads. And you don't need any local store.
I found in all cases it was (sometimes much) faster to split it into 16x1 loops which operate on 16 data items, and then have a single thread complete the partial sums.
And finally the one case where it seemed to have traction - calculating an integral image where every pixel has it's value added to every pixel to the right/below it - did seem faster than another implementation I had. But that initial implementation was before I had discovered other performance improvements so I suspect I could probably do better if i had another go. To satisfy my curiosity I just tried implementing part of it using a looping implementation and with little effort managed to beat or at least equal the prefix-sum version. Incidentally both require splitting the problem into smaller parts and then a final step to 'fix' the integral image - for the parallel prefix sum version you run out of local store or threads, and in both cases you need the parallelism to help improve the GPU efficiency.
Further Thoughts 14/9/11
Since writing this a lot more water has flowed under the bridge and I have a few more thoughts to add.
Having a smaller rather than larger work-size is important as I alluded to above: but larger problems can be made smaller by storing intermediate values in registers and then only sharing the work to reduce a smaller-multiple of the dataset. e.g. storing 4 registers locally allows 4x as much data to be 'processed' using the same amount of shared-work (and shared memory too) - which is the expensive stuff.
Since I was sticking to spec I have never tried removing the barriers and relying on the hardware's behaviour. So I don't know how much difference this makes: the technique in the paragraph above is even more useful then, if you can reduce the problem to the 64 elements required to benefit from the hardware characteristics.
The Integral Image code in socles uses these techniques, and in this case the parallel prefix sum was a (small) win. And IMHO is a fairly tight bit of code.